SQL Server 2000 Query Optimisation
10. SQL Server Optimisation
This section describes how application design can affect server performance and provides general hints for optimising SQL Server performance.
Query Optimisation
Many database applications retrieve a results set of data from the server using a SELECT statement and then selectively update individual records as they are changed by the user.
SELECT statements are passed through a query optimiser which determines the most efficient way to optimise the query. The optimiser will look at the size of the table and the indexes defined as well as information on the distribution of records within each index and will determine which index to use to improve performance.
Some queries will require a table scan which passes through all records in the table before determining which records are required in the query. Other more complex queries will perform combinations of index searching and table scanning to create the final results set.
Update Statistics
SQL Server looks at the distribution of records within each index before determining the optimisation plan. The distribution available to the optimiser is created when the index is first put on the table. Many indexes are created on empty tables and after some months of operation the optimiser will still not have any knowledge of the distribution of data and may be considering Table Scans instead of index searches.
It is therefore extremely important that these index statistics are updated after the structure of the index is changed by the addition of modification of an amount of data. This is particularly true in the first months of system use and should also be performed regularly by the system manager.
The UPDATE STATISTICS command is used to update the index distributions statistics on a table and may be called from ISQL:
UPDATE STATISTICS authors
A batch file could be created and run periodically from the ISQL or from a maintenance program written using pass through queries.
Everybody gets caught out by UPDATE STATISTICS. Remember to perform this operation on every table after uploading test data.
Index Design
Definition of appropriate indexes is the single most important performance optimisation technique. The indexes should reflect the expressions used in the WHERE clause of the most frequently used queries.
The following query based on the Authors surname requires an index on the AU_LNAME field for an index as opposed to a table scan to be used:
SELECT au_fname forename, au_lname surname
FROM authors
WHERE au_lname LIKE 'C%'
Many queries in SQL Server are not case sensitive by default which simplifies query design.
The expressions used in the Where clause must be recognisable by SQL Server as part of an index. The above example would not recognise that the surname index could be used if it had been written in this form:
SELECT au_fname forename, au_lname surname
FROM authors
WHERE substring(au_lname,1) = 'C'
Take care with wildcard characters at the beginning of expressions because they will not allow an index search:
SELECT au_fname forename, au_lname surname
FROM authors
WHERE au_lname LIKE '%opulos'
The Not Equal To operator is not optimised in SQL Server so the following query will not use an index defined on the price for a search:
SELECT * FROM titles WHERE price <> 10.00
It should be replaced with:
SELECT * FROM titles WHERE price < 10.00 OR price > 10.00
More complex queries will still use a single index for optimising the query. A search on surname and forename will still use only a single index. Thus a compound index with both the surname and firstname field will help to optimise the following query:
SELECT au_fname forename, au_lname surname
FROM authors
WHERE au_lname LIKE 'C%' AND au_fname LIKE 'S%'
In general the field that has the largest range of distinct values should be chosen as the first field in the index provided that both fields are used in the major queries.
It is important that the expressions that are used in most queries are placed as the first columns in the index. Suppose a third query on the Authors table required the CONTRACT field as an expression:
SELECT au_fname forename, au_lname surname
FROM authors
WHERE au_lname LIKE 'C%' AND au_fname LIKE 'S%'
AND contract = 1
Adding the Contract field into the index would further optimise the query. However perhaps a fourth query requiring only the surname and contract fields is also required:
SELECT au_fname forename, au_lname surname
FROM authors
WHERE au_lname LIKE 'C%' AND contract = 1
For this query to be fully optimised an index on Surname and Contract only is required. The previously defined index contains the Surname, Firstname, and Contract fields but the Firstname field is not used in this query and will prevent the optimiser from fully optimising the query. The optimiser is likely to use the index to perform the search on the Surname field but will then have to scan through all the Authors whose Surnames begin with C. A second index defined on Surname and Contact fields will allow this query to be optimised.
There is a performance penalty associated with having too many indexes on a table particularly when large numbers of transactions are being made on a table. A trade off between adding new indexes and having partially optimised queries is a necessary part of database design.
Some queries are able to use an index to process a query without looking at the table data. These covered indexes contain all the fields specified in the fields clause and the where clause and are particularly useful for summary calculations.
The following select statement would be satisfied by a covered index on the product type and the quantity:
SELECT SUM(qty) FROM sales GROUP BY prodtype
Ordering
The Order By clause can destroy performance on the server particularly if a large results set is required.
SQL Server will create a worktable for sorting in the tempdb database if the ordering criteria is not fully satisfied by the index used by the optimiser for the selection criteria. This index needs to be determined or specified by the programmer to ensure efficient ordering.
The clustered index is used often in the ordering process to prevent the requirement for a worktable. An analysis of the order required on a table will often lead to the choice of clustered index and a restriction on the ordering permitted for efficient processing.
The server may chose to use the clustered index rather than the specified index in an order by clause which prevents the server from returning the results set until the selection is completed. The FASTFIRSTROW optimiser hint allows the server to use the nonclustered index and returns the first row faster. This is useful for asynchronous queries.
Showplan
The ISQL tool allows access to the plan that the optimiser is making to optimise a query. Once a query has been identified as a potential bottleneck this window can be used to see the exact optimisation plan that SQL Server is following.
Copy the relevant SELECT statement out from the application and paste into the QUERY Page of the ISQL tool ensuring that the correct Database is selected.
Select the QUERY OPTIONS menu item from the QUERY menu and chose the SHOW QUERY PLAN option. The Results Page will show the tables scans or indexes used to perform the query and indicate if indexes may need to be added to optimise the query.
Showplan Results
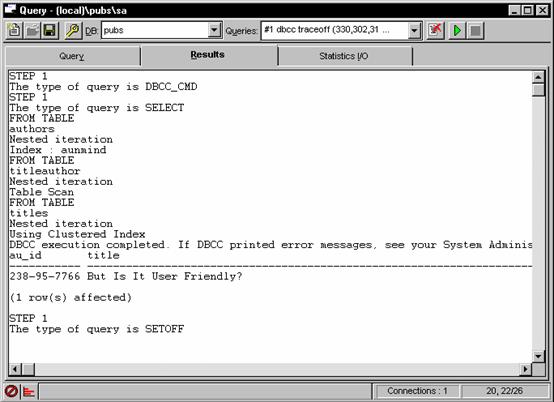
Selecting NO EXEC from the QUERY menu will create the optimisation plan without performing the query.
The STATISTICS I/O Page will show the logical and physical disk reads and if the query takes a long time and can be specified in the QUERY menu option.
The DBCC TRACEON command may be issued to show additional query optimisation statistics. This can selectively display the join order chosen by the optimiser, the estimated costs in terms of disk reads. The following command will show an abundance of optimiser information when performed with the Statistics and Execution Options set:
dbcc traceon (330,302,310,3604)
select authors.au_id, titles.title, titles.ytd_sales
from authors, titleauthor, titles
where authors.au_id = titleauthor.au_id
and titles.title_id = titleauthor.title_id
and au_lname like 'C%'
SQL Trace
SQL Server 6.5 boasts a new utility that allows monitoring of SQL Server operation whilst a live application is running. This can be useful for analysing which queries are being run in a production environment.
Monitoring Server Operation with SQL Trace

Optimiser Hints
Optimiser hints may be specified on a SELECT statement that force the query optimiser to use the specified index. The cost criteria the SQL Server assigned to a query are complex and it is likely that the statistics have not been updated or that an appropriate index has not been defined if SQL Server is selecting the wrong query path.
The optimiser hints exist to override the optimiser and helps to overcome holes in the design of the optimiser where unoptimised queries slip through. Many of these have been patched and the optimiser should be better at determining the best access path to data than all but the most experienced database administrators. It is recommended that optimiser hints are only employed where it proves impossible for the optimiser to recognise the required indexes/
One trick to force the optimiser into considering alternative query paths is to change the join order of a multi table query. The optimiser determines the join order early in the optimisation process and changing the join order may force it to reconsider and choose a faster query path. Alternatively split the query up into several simple selects to give the optimiser a set of less complex join optimisations.
Clustered Indexes
Each table may have a clustered index which physically sorts the table into a particular order. This is useful where many processes require that the table is processed in a particular order. Transactions in an accounting system for example are often accessed in date order and a clustered index on the date might seem to be appropriate at first glance.
Clustered Indexes are useful for optimising queries on a range of values such as a date range.
Adding new records to any table will require updates on the table and all associated indexes. Data is stored on the disk in logical pages and once that appropriate page is found, the page is locked and the data written in the correct place. Each page however may contain data relating to more than one record and several users may require to write to the same page at the same time. The server will of course handle this contention.
Clustered indexes will place sorted data into the pages so that sorted records may be next to each other in the same page. When two new records are added in a table with a sorted index on the date, for example, they may be added into the same page. The users are competing for the same resource and a bottleneck occurs.
Clustered indexes should not therefore be defined on a sort order that is the same or similar to the sort order of new records as they are added as this would cause contention in high transaction systems.
SQL Server 6.5 improves on this bottleneck but care is still required when selecting the clustered index.
Index Tuning Wizard
Stored Procedure Recompilation
Queries are often used within stored procedures to perform a variety of tasks. The query plan is determined when the stored procedure is initially compiled and is not updated even when the UPDATE STATISTICS command is run on a table that is used in the query.
The procedure may be executed with a recompile option to force recompilation of the procedure at runtime. This will ensure that the optimiser is used in any queries but is costly as the server must perform extra work each time the procedure is executed:
exec byroyalty 40 with recompile
Another option is to define the Stored Procedure with the Recompile option by adding the WITH RECOMPILE keywords in the CREATE PROCEDURE syntax of the stored procedure definition.
This forces the stored procedure to be recompiled each time it is executed and is suitable if the stored procedure is called infrequently and requires different query plans each time. This might occur if parameters were passed that sometimes access only a few records and other times the whole table.
Recompilation each time is inefficient and not suitable for stored procedures that are in constant use.
A system stored procedure can be used to automatically recompile each stored procedure that references a particular table. This stored procedure is best run after the statistics for the table have been updated.
The following example will update statistics on the Authors table and recompile the query plans for any stored procedure that used the Authors table:
UPDATE STATITICS authors
sp_recompile authors
Creating a Stored Procedure with Recompile
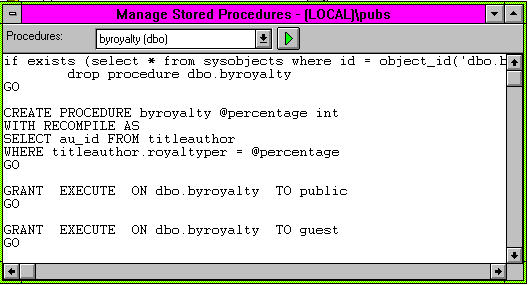
Sophisticated programmers may find that the optimisation for a stored procedure differs according to the parameters passed to the procedure if the number or records selected varies considerably for example. Several stored procedures may be written and run with parameters defined to optimise the query for that particular type of parameter value. Alternatively parameters can be used in the SELECT statements so the optimiser cannot determine the query plan in advance of execution.
Deferred Updates
Many SQL Server update commands use a deferred update where the changes are made the transaction log and the old record deleted and the new one inserted. This can have an adverse effect on a high transaction system.
Non-deferred, or Direct, updates 'in place' can be designed that update the record without deleting and inserting records. This requires that no changes are made to the clustered index or to variable width fields so that the changed record can remain on the same page. The table should not have a trigger that updates other table nor should columns involved in referential integrity be updates.
Direct updates not-in-place use a delete followed by an update but are performed in a single pass. These require that no join is specified and that the index used to select the records is not updated.
Locking Issues
SQL Server, in common with other servers, will use optimistic record locking by default.
SQL Server performs all internal locking at the page level. A page contains 2K worth of information and may therefore contain more than one table record. A shared lock is placed on a page whenever it is read by a user program. This shared lock is upgraded to an Update lock when the server plans to write data to a record and then to an Exclusive lock before data is actually written to any record within the page. The locking manager will resolve any deadlocks and issues where different users attempt to update the same record at the same time.
Read only databases benefit from having the read only option set so that any shared locking overhead is removed.
Locking issues come into play on high transaction systems with the potential for many deadlocks. Minimising the records read in a single transaction will reduce the number of shared locks placed on each table. This then allows SQL Server to place Update locks more efficiently and allow the programmer to program a locking strategy for critical transactions.
The BEGIN TRANSACTION statement matched with the COMMIT TRANSACTION or ROLLBACK TRANSACTION statements help to define smaller size transactions in a stored procedure.
The optimiser hints of a SELECT statement allow a programmer to specify specific and override the default use of shared locks. The HOLDLOCK option will ask the server to maintain the shared locks on a set of records until the end of the transaction.
The UPDLOCK optimiser hint will specify that a SELECT statement uses Update locks immediately instead of shared locks and can be used when the program is attempting to update all records in the select query.
Page locks are automatically escalated to table level if a specified number are issued on a single table. The SELECT statement can be used to request a shared table lock immediately without using the escalation level if all records in a table are to be processed:
BEGIN TRAN
SELECT count(*) FROM taborder (TABLOCK HOLDLOCK)
Alternatively, the PAGLOCK hint will prevent escalation to a shared table lock if this is not desirable in a high transaction system.
The Database Administrator may need to set the configuration on the database to cope with some locking scenarios.